Tags are dumb. I'm going to fix tags
Tags are dumb. They don't work and if you prefer them over folders, you're wrong.
So I'm rewriting my blog with tags as the primary mechanism of organisation. I'm going to fix tags.
What's wrong with tags?
I got an e-reader for my birthday last month. There are four (4) books on there. It still has that new-e-reader smell. And already, here's what the Tags view in Calibre looks like.
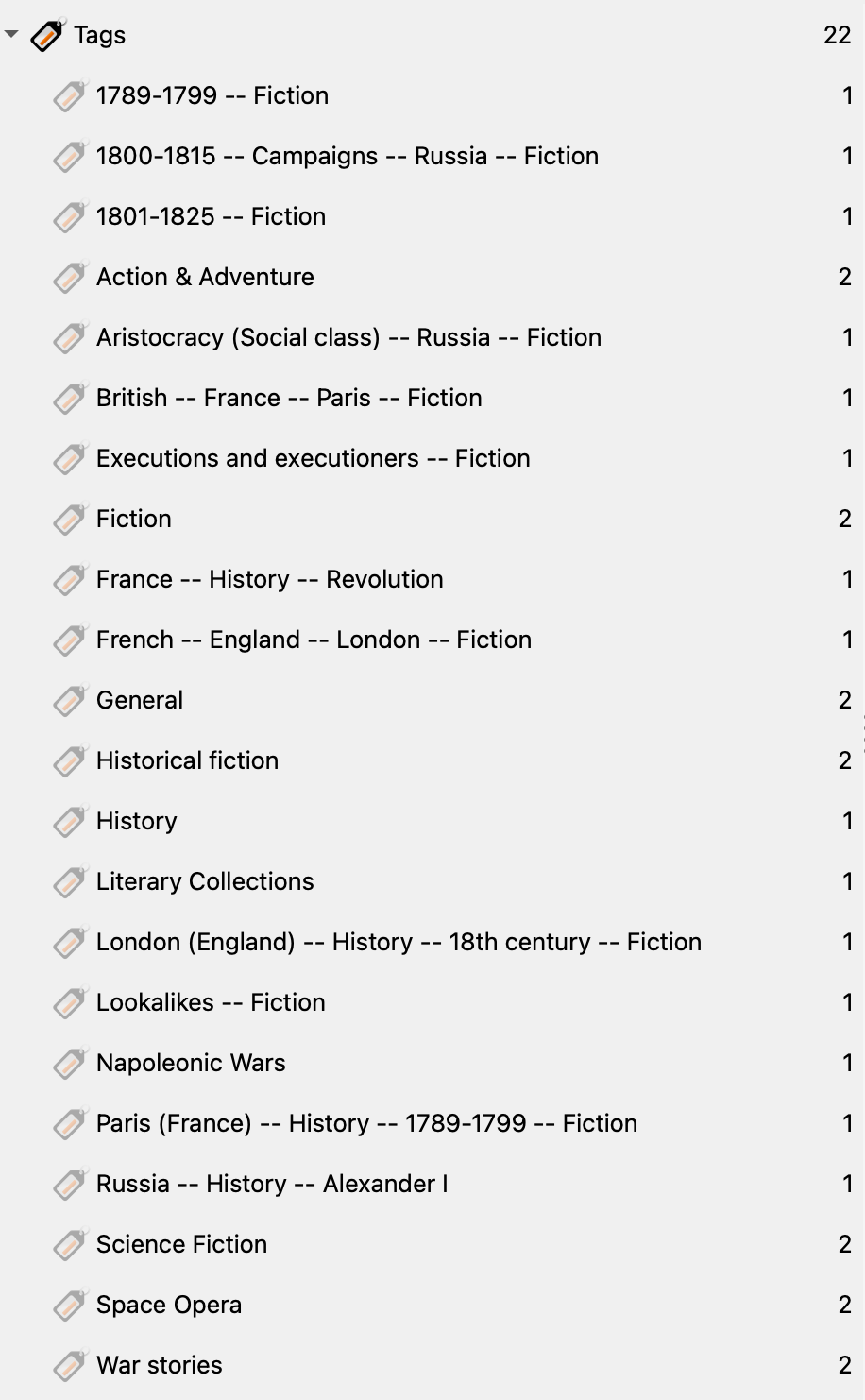
I couldn't have written a better parody. We have British -- France -- Paris -- Fiction and its cousin French -- England -- London -- Fiction, each with what I assume are some sort of clever ISO-standard double-dash separators that enforce a defined hierarchy and allow me to expand/collapse and filter at each level?
Oh that's not what they do? Oh. Well that's a shame. Also when did England morph in to British? Long before the summer of 1789, let me tell you. And I hope you didn't search for France hoping to find that second book because there it's the adjectival French.
So, as implemented, these tags are worse than useless. They're noise. I'll never, ever look at them again.
(For the record: I do see the pattern here. You don't need to email me.)
Tags: the Johnny.Decimal spec
If we were to fix tags, what are the requirements?
1. There must be no ambiguity or chance of duplication
When there is a possibility of duplication in meaning, the system cannot be trusted. If I've selected Historical fiction believing that this encompasses both history, historical fiction, and fiction, and something that I expect to be surfaced is not, my faith in the system collapses.
And these three things are, in this case, distinct entities. They should have their own tags. But I have no confidence that this is as-implemented in my system.
This requirement extends to the act of adding a new tag. In current systems this is hit-and-miss. Do I already have a suitable tag? How would I know? And so you add another, and the problem compounds.1
2. They must be organised hierarchically
Tags are generally presented as a flat list. And now we're back to Johnny's least favourite thing: the alphabet.2
Here follows a comprehensive list of things worse at presenting information than the alphabet:
1. A tag cloud
Thus ends the list.
Folders are natural
I saved something from the Obsidian Discord the other day. I'll quote it here without attribution as the point isn't to dunk on the author. In the context of a tags vs. folders discussion, they wrote:
I don't see any advantage to folders other than that they are universally intuitive and quick to implement, and that they are the default way of organizing things in operating systems.
My response was that 'this is quite the advantage though, no?'. But it speaks directly to the Foundational Principle of the Tag People: that folders are bad, because we have computers that are capable of virtually 'storing' things in multiple places (as represented by tags), so why limit ourselves to just one place (the humble folder)?3
The fundamental error is that this simply isn't how people conceptualise information. How many places can your drivers licence be? One. And if you were to try to find it, how do you go about that, mentally? You start at the top and you filter down. House → hallway → that little table that holds your keys and other daily junk → wallet → licence.
If at any point in this no-doubt frustrating journey of discovery (I'm late already I know it "should be" in the hallway please can you just help me find my licence) the thing isn't where you expect, it is entirely natural to step back up the hiearchy, choose another branch, and so it goes until you realise that, inexplicably, you left your wallet in the bathroom this morning.
But Johnny, you're wilfully conflating issues here; the Tag People are talking about tagging things like photographs and book metadata, and you're talking about finding your physical licence.
Kinda, but not really. There are Tag People who really do advocate for storing all of your information using tags and not folders. But I think this is beside the point: I don't think it matters what you're using them for. They're still broken for all of the reasons outlined above.
This does speak to the defining feature of tags, which we should address.
3. You must be able to assign multiple tags to an item
This is stating the obvious, but let's make our requirements comprehensive. The entire point of tags is that many things do in fact have multiple properties, and that it can be helpful to be able to filter and group based on these properties.
Let's think about a blog. And let's expand the concept of a blog, which I'm going to do. (Working title: megablog.) Any given '(mega)blog post' might be long- or short-form. It might be a video or not. It might have a certain tone: serious, or snarky? (Like this post, it might be both.) It might be personal or work related; might relate to one or more Johnny.Decimal concepts; it might be one in a series. And so on.
You can extend this concept (which I will) to all of our written and recorded work, public or paid, and to forum posts, Discord threads, and anything else.
4. There must still be a single, canonical list of All The Things
I'm acutely aware of the fact that organising your stuff is a boring chore. If it was heaps fun I'd be a rich man, amirite?
This is a fundamental problem with tags: now you have to tag everything! If you forget to tag that important finance spreadsheet with either important or finance, then now what? Where is it?4
And who thinks to go back and re-tag stuff, or to add helpful tags to already-tagged data, or to consolidate tags? It's just never going to happen. Whereas at least the catastrophe that is your work's g:\finance folder is browsable. Every finance spreadsheet is in there somewhere.
So I suggest – this is a soft requirement, as yet unexplored – that every system that uses tags must also have some sort of canonical list by which every item can be referenced. I'm starting with my blog, and expanding to all other content, so in my case it's easy to see how a simple linear ID, or a Johnny.Decimal ID, can accommodate this requirement.5
The point is that tags are additive. They do not replace existing methods of organisation.
Note: this does not replace your filesystem
Just so it's clear: I do not intend to replace my filesystem with tags. I am developing this as an idea, for a very specific use-case: published multi-media content.
I already know where to look for my licence. It's in my wallet, and the electronic artefacts are at 10-19 Life admin / 11 Me & other living things / 11.14 Licences. No part of me seeks to add tags to this system.
How? Johnny.Decimal
Conveniently enough, I have a system that meets these requirements. I believe that the solution is as simple as tags, organised per the basic rules: hierarchically, in groups of no more than 10 and 10 again, and then assigned a unique ID.
We will lean heavily on a core Johnny.Decimal principle: fewer is better and close enough is good enough.6 Only create a new tag when absolutely necessary; if an existing tag is good enough, use it.
That's it. I don't know if it'll work, but I can't see why not. And could it possibly be worse than what we have now? Let's find out.
Next: 'dynamic discovery'
We already have a hierarchy that describes all books. Why invent the nonsense that is British -- France -- Paris -- Fiction when we already have 823 English fiction, 942 English history, and 944 French history?7 Just use those as your tags!
But my megablog isn't books, so I need my own system of tags. Assuming you're not the city librarian, you'll also need your own. Coming up with one sounds onerous, but I think I have another idea: dynamic discovery. That's the next post.
100% human. 0% AI. Always.
Footnotes
-
Nicely demonstrated by this Reddit comment from 5 years ago, whose experience exactly mirrors mine: 'I'm sure there are hundreds of genres. I have 46 listed in my library & I don't even listen to that big a variety in music.' ↩
-
Just kidding, the alphabet is great. If you're writing the dictionary. For almost everything else, it's a terrible way to organise information. Concepts are not alphabetical. Concepts are hierarchical. ↩
-
I know that your computer virtually 'stores' files as inode references and that tags might be, in this regard, conceptually more pure than folders. You don't need to email me about that either. ↩
-
This reveals another interesting fact. I didn't say that you should tag the spreadsheet with
spreadsheet, because it already is, by virtue of its.xlsxfile extension. This feels natural and shouldn't be a surprise. But how many of you know that you can trivially search your filesystem for specific file extensions, revealing all spreadsheets at a glance? Or group the view in your file explorer by type of file? Or create saved 'search folders' that show all spreadsheets by last updated date? And how many of you actually use these features on any given day? (I'll show you how, it's on my to-do list.) ↩ -
This linearity serving to anchor the item in time and space, aiding discoverability. Humans naturally place things in a temporal context. I know I created this after I wrote that, or I remember where I was when I wrote that, and it must have been around September 2025. This feature comes free with your brain; you might as well use it. ↩
-
The only time when 'good enough' is an acceptable standard. ↩
-
Technically, the reason for this nonsense is that the authors have tried to shoehorn a tag hierarchy in to a string. This is because most tag systems are implemented as a flat list, precluding any built-in representation of hierarchy. But this reveals yet another footnote-relegated insight: tags must only be used where they are a fully supported, first-class citizen. I'll be building custom tag support for the megablog. ↩